2013 年我接触 Python 的时候,就听闻 Python 的网络编程能力十分强大。因此,在熟悉 Python 的基本语法之后,我就和几个小伙伴一起合作,试着用 Python 的 urllib 和 urllib2 库构建了一个百度贴吧 Python 客户端。
然而,使用的过程中,我发现两个标准库的语法并不自然,甚至可以说十分反人类——用着很难受。又有,我平时使用 Python 甚少涉及到网络编程的内容。因此,Python 的网络编程就被我放下了,直到我认识了 requests 库。
requestsrequests 库的宣言是
HTTP for Humans (给人用的 HTTP 库)
我们首先来验证一下。
在网络编程中,最最基本的任务包含:
我们以 GitHub 为例,先看一下使用 urllib2 要怎么做。为了把事情弄简单点,我们假设实现已经知道,GET 请求 https://api.github.com/ 返回的内容是个 JSON 格式的数据(实际上通过 content-type 也能判断)。
1 import urllib2
如果运行正确,那么代码应该返回:
1 issues_url https://api.github.com/issues
同样的效果,用 requests 库则有如下代码:
1 import requests
溢美之词就不用说了,读到这里的你心里肯定只有一声「卧槽,这才是 Python 该有的样子」。那么,接下来我们看看 requests 都有哪些黑魔法。
最推荐的方式,是直接安装推荐过的 Anaconda 。
如果你不想安装 Anaconda,那么建议你使用 pip 安装;只需在命令行下执行:
requests 的基本用法,呃,真是不能再基本了。最基本的操作,就是以某种 HTTP 方法向远端服务器发送一个请求而已;而 requests 库就是这么做的。
1 import requests
从语法上看,requests 库设计的非常自然。所谓 requests.get,就是以 GET 方式发送一个 REQUEST,得到一个 Response 类的结果,保存为 r 。
你可以在 r 中取得所有你想得到的和 HTTP 有关的信息。下面,我们以 GET 方法为例,依次介绍。
如果你经常上网(废话,看到这里的都上过网吧……),一定见过类似下面的链接:
https://encrypted.google.com/search?q=hello
即:
1 <协议>://<域名>/<接口>?<键1>=<值1>&<键2>=<值2>
requests 库提供的 HTTP 方法,都提供了名为 params 的参数。这个参数可以接受一个 Python 字典,并自动格式化为上述格式。
1 import requests
运行将得到:
1 http://www.so.com/s?q=query&ie=utf-8
requests 库定义的 Response 类可以方便地获取请求的 HTTP 状态码和重定向状态。
360 公司的搜索引擎,原名「好搜」,现在改为「360 搜索」;域名也从 www.haosou.com 改成了 www.so.com。如果你在地址栏输入 www.haosou.com,那么会经由 302 跳转到 www.so.com。我们借此来演示。
1 import requests
结果是:
1 http://www.so.com/s?q=query&ie=utf-8 200
我们发现,requests 默认自动地处理了 302 跳转。在经过跳转的请求中,返回的 URL 和状态码都是跳转之后的信息;唯独在 history 中,用 Python 列表记录了跳转情况。
大多数情况下,自动处理是挺好的。不过,有时候我们也想单步追踪页面跳转情况。此时,可以给请求加上 allow_redirects = False 参数。
1 import requests
输出结果:
1 http://www.so.com/s?q=query&ie=utf-8 200
不允许 requests 自动处理跳转后,返回的 URL 和状态码都符合预期了。
requests 的超时设置以秒 为单位。例如,对请求加参数 timeout = 5 即可设置超时为 5 秒。
1 # a very short timeout is set intentionally
返回报错:
1 Traceback (most recent call last):
我们利用 httpbin 这个网站,先来看一下 requests 发出的 HTTP 报文默认的请求头是什么样子的。
1 import requests
返回结果:
1 {
注意,这里使用 r.content 来查看请求头部是因为 httpbin 这个网站的特殊性——它什么也不干,就把请求的内容返回给请求者。在 requests 当中,应当使用 r.request.headers 来查看请求的头部。
通常我们比较关注其中的 User-Agent 和 Accept-Encoding。如果我们要修改 HTTP 头中的这两项内容,只需要将一个合适的字典参数传给 headers 即可。
1 import requests
返回:
1 {
可以看到,UA 和 AE 都已经被修改了。
作为 HTTP 请求的响应,返回的内容中也有 HTTP 头。它是一个反序列化为 Python 字典的数据结构,可以通过 Response.headers 来查看。
1 import requests
返回:
1 {
长期以来,互联网都存在带宽有限的情况。因此,网络上传输的数据,很多情况下都是经过压缩的。经由 requests 发送的请求,当收到的响应内容经过 gzip 或 deflate 压缩时,requests 会自动为我们解包Response.content 来获得以字节形式返回的相应内容。
1 import requests
这相当于 urllib2.urlopen(url).read()。
如果相应内容不是文本,而是二进制数据(比如图片),那么上述打印结果可能会糊你一脸。这里以图片为例,示例一下该怎么办。
1 import requests
运行无误的话,能看到我和我爱人的照片。
如果响应返回是文本,那么你可以用 Response.text 获得 Unicode 编码的响应返回内容。
1 import requests
要获得 Unicode 编码的结果,意味着 requests 会为我们做解码工作。那么 requests 是按照何种编码去对返回结果解码的呢?
requests 会读取 HTTP header 中关于字符集的内容。如果获取成功,则会依此进行解码;若不然,则会根据响应内容对编码进行猜测。具体来说,我们可以用 Response.encoding 来查看/修改使用的编码。
1 import requests
开篇给出的第一个 requests 示例中,特别吸引人的一点就是 requests 无需任何其他库,就能解析序列化为 JSON 格式的数据。
我们以 IP 查询 Google 公共 DNS 为例:
1 import requests
结果将输出:
HTTP 协议是无状态的。因此,若不借助其他手段,远程的服务器就无法知道以前和客户端做了哪些通信。Cookie 就是「其他手段」之一。
Cookie 一个典型的应用场景,就是用于记录用户在网站上的登录状态。
用户登录成功后,服务器下发一个(通常是加密了的)Cookie 文件。 客户端(通常是网页浏览器)将收到的 Cookie 文件保存起来。 下次客户端与服务器连接时,将 Cookie 文件发送给服务器,由服务器校验其含义,恢复登录状态(从而避免再次登录)。 requests 中Cookie? 你说的是小甜点吧!
别忘了,requests 是给人类设计的 Python 库。想想使用浏览器浏览网页的时候,我们没有手工去保存、重新发送 Cookie 对吗?浏览器都为我们自动完成了。
在 requests 中,也是这样 。
当浏览器作为客户端与远端服务器连接时,远端服务器会根据需要,产生一个 SessionID,并附在 Cookie 中发给浏览器。接下来的时间里,只要 Cookie 不过期,浏览器与远端服务器的连接,都会使用这个 SessionID;而浏览器会自动与服务器协作,维护相应的 Cookie。
在 requests 中,也是这样。我们可以创建一个 requests.Session,尔后在该 Session 中与远端服务器通信,其中产生的 Cookie,requests 会自动为我们维护好
POST 方法可以将一组用户数据,以表单的形式发送到远端服务器。远端服务器接受后,依照表单内容做相应的动作。
调用 requests 的 POST 方法时,可以用 data 参数接收一个 Python 字典结构。requests 会自动将 Python 字典序列化为实际的表单内容。例如:
1 import requests
返回:
1 {
模拟登录的第一步,首先是要搞清楚我们用浏览器登录时都发生了什么。
GitHub 登录页面是 https://github.com/login 。我们首先清空浏览器 Cookie 记录,然后用 Chrome 打开登录页面。
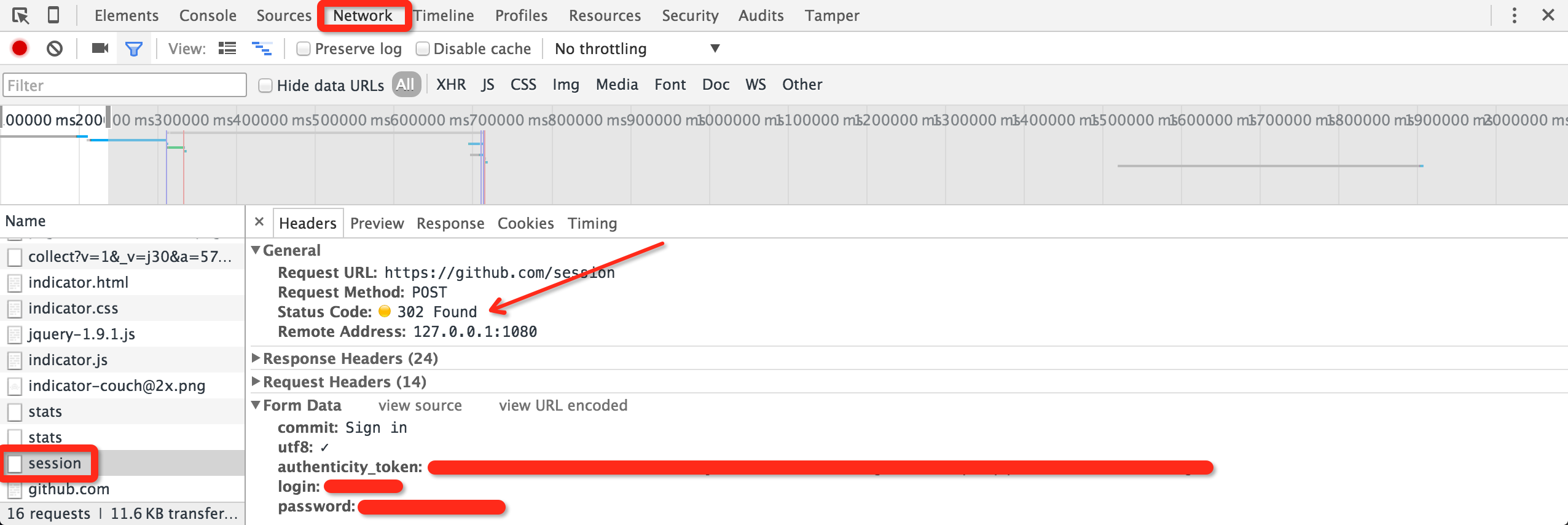
填入 Username 和 Password 之后,我们打开 Tamper Chrome 和 Chrome 的元素审查工具(找到 Network 标签页),之后点登录按钮。
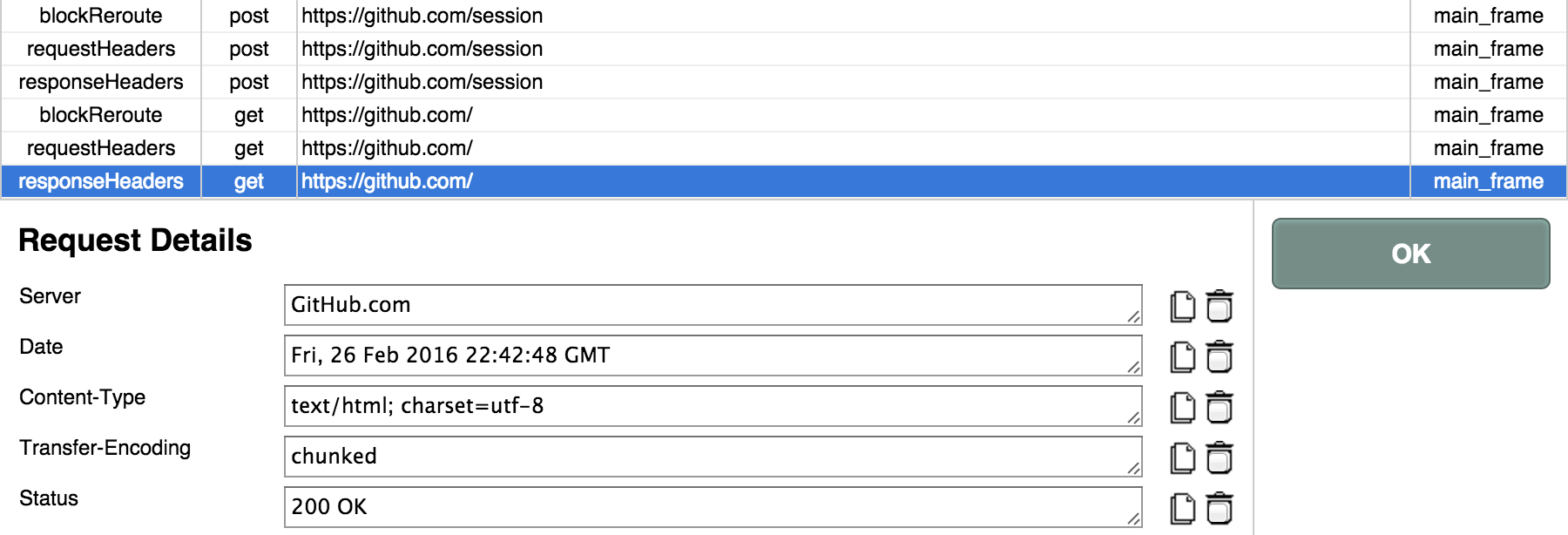
在 Tamper Chrome 中,我们发现:虽然登录页面是 https://github.com/login ,但实际接收表单的是 https://github.com/session 。若登录成功,则跳转到 https://github.com/ 首页,返回状态码 200。
而在 Chrome 的审查元素窗口中,我们可以看到提交给 session 接口的表单信息。内里包含
commitutf8authenticity_tokenloginpassword
其中,commit 和 utf8 两项是定值;login 和 password 分别是用户名和密码,这很好理解。唯独 authenticity_token 是一长串无规律的字符,我们不清楚它是什么。
POST 动作发生在与 session 接口交互之前,因此可能的信息来源只有 login 接口。我们打开 login 页面的源码,试着搜索 authenticity_token 就不难发现有如下内容:
1 <input name="authenticity_token" type="hidden" value="......" />
原来,所谓的 authenticity_token 是明白卸载 HTML 页面里的,只不过用 hidden 模式隐藏起来了。为此,我们只需要使用 Python 的正则库解析一下,就好了。
这样一来,事情就变得简单起来,编码吧!
模拟登录 GitHub 1 import requests
输出:
1 https://github.com/ 200 [<Response [302]>]
代码很好理解,其实只是完全地模拟了浏览器的行为。
首先,我们准备好了和 Chrome 一致的 HTTP 请求头部信息。具体来说,其中的 User-Agent 是比较重要的。而后,仿照浏览器与服务器的通信,我们创建了一个 requests.Session。接着,我们用 GET 方法打开登录页面,并用正则库解析到 authenticity_token。随后,将所需的数据,整备成一个 Python 字典备用。最后,我们用 POST 方法,将表单提交到 session 接口。
最终的结果也是符合预期的:经由 302 跳转,打开了(200)GitHub 首页。